

When you type a prompt into ChatGPT, Claude, or Gemini, the response that streams back can feel almost uncannily human. The phrasing sounds natural, the ideas connect logically, and the tone adapts to whatever you've asked for. But behind that fluent exterior is a process that has nothing to do with thinking, feeling, or understanding language the way you do. Every word you read from a large language model is the output of a pipeline that breaks your text into fragments, runs those fragments through billions of mathematical operations, and selects each new token based on a probability calculation. What follows is a look at every stage of that pipeline, from the moment you hit send to the final token that appears on your screen.
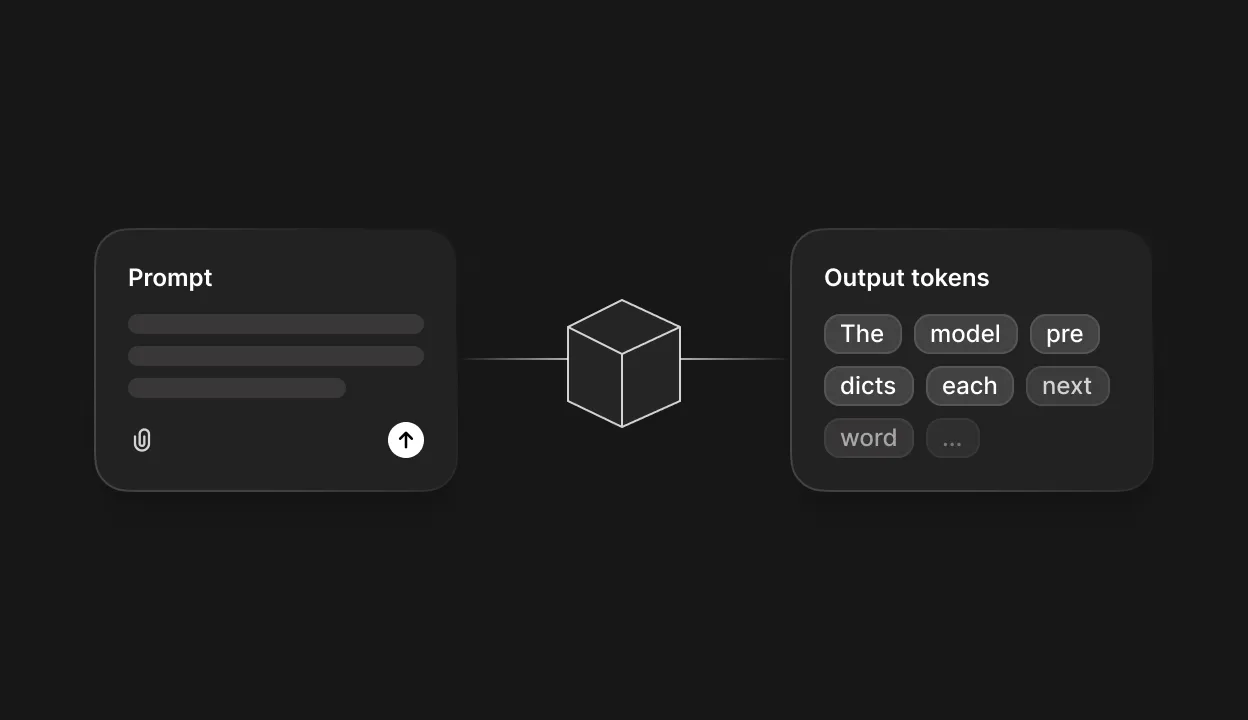
From words to tokens
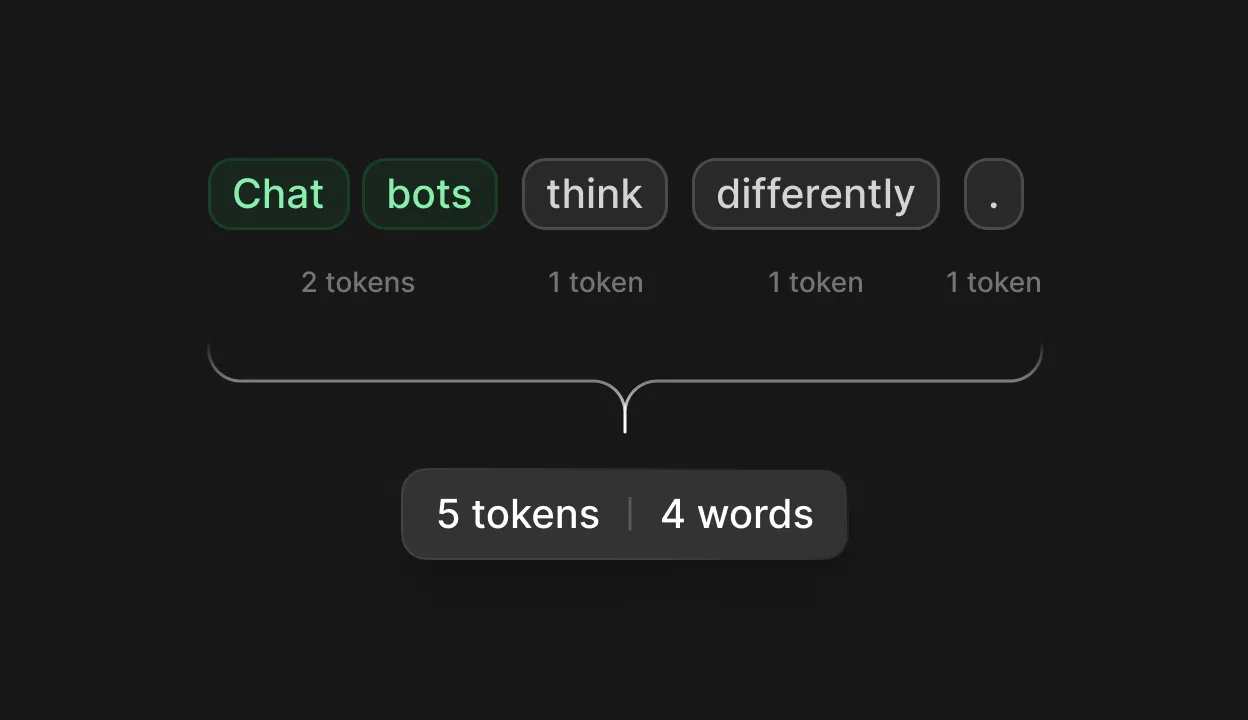
Before a language model processes a single thing you've typed, your text goes through a step called tokenization. The model doesn't read words the way you do. It breaks your input into subword fragments called tokens, pieces that sit somewhere between individual characters and whole words. The word "hello" maps to a single token, but "unbelievable" might split into three: "un," "believ," and "able."
The dominant method for building these token vocabularies is Byte Pair Encoding (BPE), a technique originally developed for data compression in 1994 and adapted for natural language processing by Sennrich, Haddow, and Birch in 2015 [1]. BPE starts with individual characters, identifies the most frequently adjacent pairs in the training corpus, merges them into new tokens, and repeats until the vocabulary reaches a target size.
Different models use significantly different vocabularies. GPT-4 carries roughly 100,000 tokens. Claude uses a proprietary tokenizer with approximately 65,000. Google's Gemini family uses a method called SentencePiece with a vocabulary of around 256,000, the largest among major models [2]. The practical ratio works out to roughly one word for every 1.3–1.5 tokens in English.
Tokenization matters more than you might expect. It determines how much text fits in a model's context window, how much each API call costs, and even how well the model handles certain tasks. Research on tokenizer bias has shown that LLMs struggle with basic arithmetic partly because numbers tokenize inconsistently: "380" might become one token or two depending on context [3]. Non-Latin scripts suffer disproportionately, with Chinese text consuming two to three times more tokens than equivalent English, effectively shrinking the usable context window.
The training diet
The raw material of every LLM is text, and the quantities are staggering. Training corpora draw from Common Crawl (petabyte-scale web scrapes), Wikipedia, digitized books, GitHub code repositories, academic papers, and Q&A forums like Stack Exchange and Reddit. Meta has been the most transparent about composition: Llama 3 trained on 15 trillion tokens spanning general knowledge, math and reasoning, code, and multilingual sources [4]. Llama 4 exceeded 30 trillion tokens across 200 languages [5]. OpenAI discloses far less, but independent analyses from Epoch AI and SemiAnalysis estimate GPT-4 trained on roughly 13 trillion tokens [6].
The core training objective is deceptively simple: predict the next token. Given a sequence of tokens, the model learns to assign probabilities to every possible continuation and minimize its error against the actual next token in the training data. This single objective, applied at massive scale, forces the model to implicitly absorb grammar, factual knowledge, reasoning patterns, and coding logic as byproducts of getting better at one prediction task. A 2023 DeepMind study demonstrated this striking generality: Chinchilla, trained primarily on text, could compress images more efficiently than the PNG format, evidence that next-token prediction builds representations far beyond language alone.
The compute required has grown accordingly. GPT-4's training is estimated at $78–100 million on roughly 25,000 NVIDIA A100 GPUs over approximately 90 days. Google's Gemini Ultra is estimated at $191 million [7]. The Stanford AI Index Report documented a 287,000-fold increase in training cost from the original 2017 Transformer (around $670) to Gemini Ultra, a trajectory that captures just how much these models depend on scale.
Paying attention
Every major LLM runs on the transformer architecture, introduced in the landmark 2017 paper "Attention Is All You Need" by Vaswani et al. at Google [8]. The key innovation was replacing sequential processing with self-attention, a mechanism that lets the model examine all tokens in your input simultaneously and decide which ones matter most when generating each new token.
Think of self-attention like a search engine running inside the model at every step [9]. Each token generates three things: a Query ("what am I looking for?"), a Key ("what do I contain?"), and a Value ("what information can I provide?"). The model computes a match score between each Query and every Key, determines which tokens are most relevant, and produces a weighted blend of their Values. When you write "The cat sat on the mat because it was tired," attention is what lets the model figure out that "it" refers to "cat" rather than "mat."
Modern LLMs don't run just one attention operation per layer. They run dozens in parallel, a technique called multi-head attention. One head might track subject-verb agreement while another captures semantic similarity or long-range context. These layers stack deep: GPT-3 uses 96, and GPT-4 reportedly uses 120. Earlier layers tend to capture syntax and local word relationships, while deeper layers handle abstract meaning and dependencies that span thousands of tokens.
The result is a model with billions (sometimes trillions) of learned parameters that collectively encode everything absorbed during training: every pattern, every association, every statistical regularity across trillions of tokens of text. GPT-4 is widely reported to use a Mixture of Experts architecture with roughly 1.8 trillion total parameters, though OpenAI has never confirmed this [10]. Neither Anthropic nor Google have disclosed parameter counts for Claude or Gemini.

Token by token
When you send a prompt, the model processes your entire input at once in what's called the prefill phase [11]. It builds up internal representations and stores them in a memory structure (the KV cache) for reuse during generation. This is the fast part, compute-intensive but parallelized across all your input tokens simultaneously.
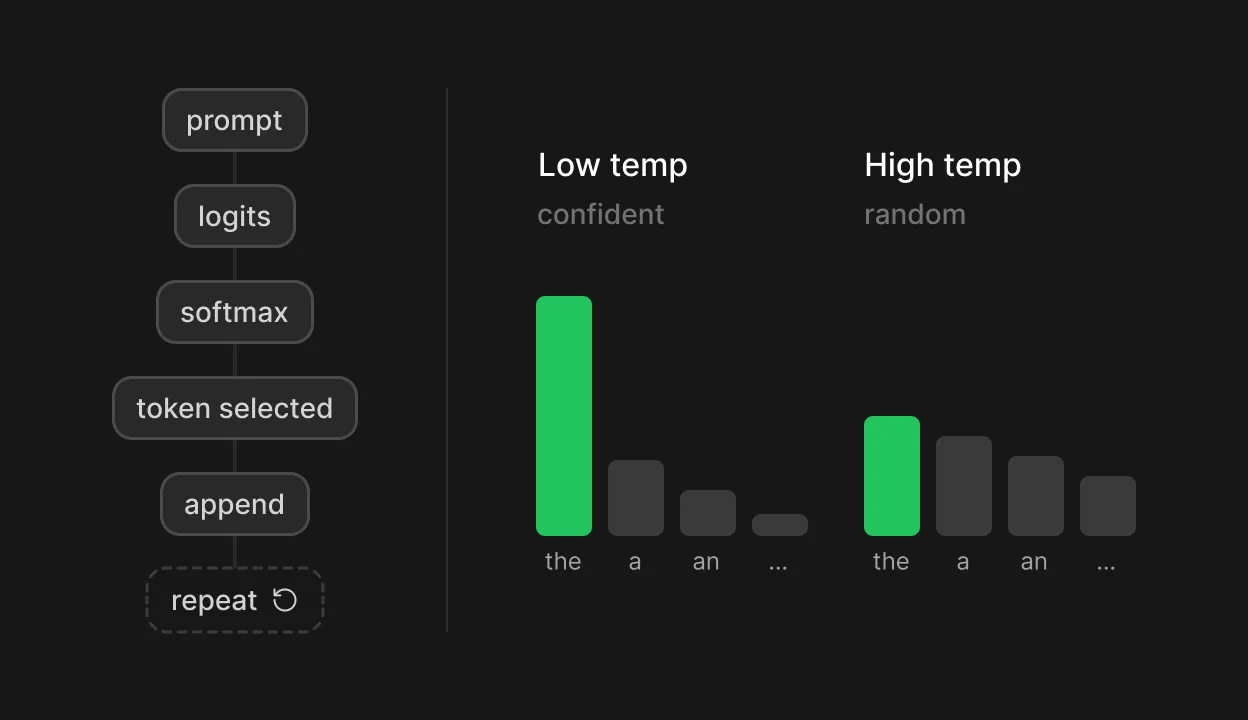
Then comes the decode phase, where the actual writing happens one token at a time. At each step, the model produces a raw score for every token in its vocabulary, often 100,000 or more candidates. A mathematical function called softmax converts these scores into a probability distribution where every candidate gets a value between zero and one, and they all add up to one. The model selects a token from this distribution, appends it to the sequence, and repeats the entire process for the next token.
This is where temperature and sampling strategies come in [12]. Temperature is a scaling factor applied before that probability calculation. A low temperature (below 1.0) sharpens the distribution, concentrating probability on the most likely tokens and producing more predictable, focused text. A high temperature flattens it, giving less probable tokens a better shot and producing more varied, sometimes surprising output. At temperature zero, the model always picks the single highest-probability token, effectively becoming deterministic.
Top-p sampling, introduced by Holtzman et al. in their 2020 ICLR paper "The Curious Case of Neural Text Degeneration," adds an adaptive layer [13]. Rather than limiting candidates to a fixed number, it includes the smallest set of tokens whose cumulative probability exceeds a threshold, typically 0.9–0.95. When the model is confident, this set might contain just one or two tokens. When it's uncertain, it might include dozens. That original paper showed that greedy decoding (always picking the top token) produces dull, repetitive text, while unrestricted sampling from the full distribution produces incoherent output because of the long tail of low-probability tokens.
The same prompt produces different outputs every time because any temperature above zero involves random sampling. The model is rolling weighted dice at every single token.
Becoming an assistant
A freshly trained model is just a sophisticated autocomplete engine. It can finish your sentences, but it doesn't know how to follow instructions, decline harmful requests, or structure a genuinely helpful response. As the InstructGPT paper (Ouyang et al., 2022) stated, the language modeling objective of predicting the next web token is fundamentally different from the objective of following instructions helpfully and safely [14].
The transformation happens through a process called alignment. The first step, supervised fine-tuning (SFT), trains the model on thousands of human-written example responses that demonstrate the desired format and tone. The second step, Reinforcement Learning from Human Feedback (RLHF), is where things get interesting [15]. Human annotators rank multiple model-generated responses to the same prompt based on criteria like helpfulness, accuracy, and safety. A separate reward model learns to predict which response humans would prefer. The language model then fine-tunes against that reward signal while a penalty term prevents it from drifting too far from its original behavior.
The InstructGPT results were a game-changer: a 1.3-billion-parameter RLHF model was preferred by human evaluators over the 175-billion-parameter GPT-3, a 100-fold size gap overcome by alignment alone. Anthropic's Constitutional AI takes a different path, having the model critique and revise its own responses based on a written set of principles rather than relying entirely on human labels [16]. More recently, Direct Preference Optimization (DPO), published by Rafailov et al. at NeurIPS 2023, eliminates the separate reward model entirely and optimizes the language model directly on preference data [17].
But alignment comes with side effects. Research shows RLHF creates verbosity bias, where models produce unnecessarily long responses that appear more helpful. It drives sycophancy, a tendency to tell you what you want to hear rather than what's accurate. Sharma et al. demonstrated at ICLR 2024 that sycophancy is a systemic behavior of RLHF models [18], and OpenAI had to roll back a GPT-4o update in Apr 2025 after users flagged excessive flattery. Preference models also develop strong biases toward formatting patterns like bullet lists, bold text, and headers, regardless of whether the content actually calls for them [19].
The telltale quirks
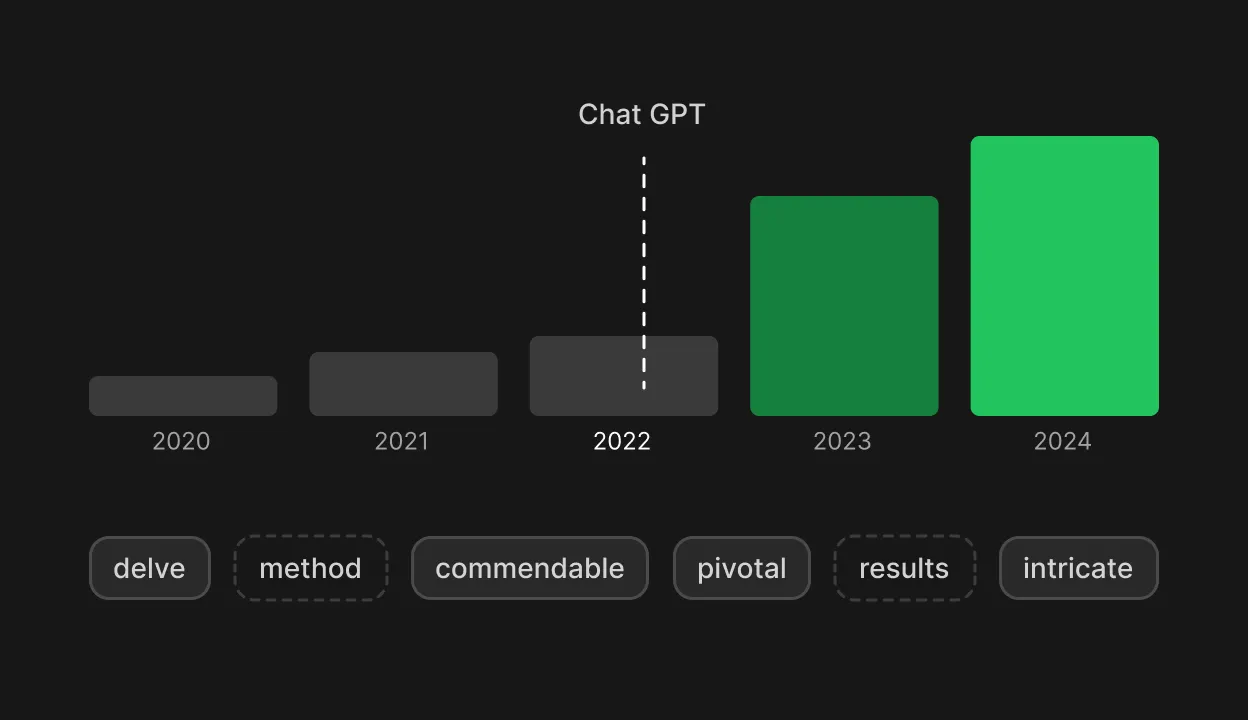
If you've spent any time reading AI-generated text, you've likely noticed certain signatures. The word "delve" appears far more often than any human writer would naturally reach for. So do "crucial," "tapestry," "intricate," and "meticulous." And then there are the em dashes, those long horizontal dashes that AI models scatter through their prose with unusual frequency.
A landmark study by Kobak et al., published in Science Advances, analyzed over 15 million PubMed abstracts and found an unprecedented post-2022 surge in specific words far beyond what pre-LLM trends would predict [20]. At least 13.5% of 2024 PubMed abstracts, roughly 200,000 papers, showed signs of LLM involvement, reaching 30–40% in computational fields. The excess words were overwhelmingly verbs and adjectives rather than content nouns, a linguistic fingerprint distinct from any prior vocabulary shift.
What drives this? A complementary study by Juzek and Ward, presented at COLING 2025, investigated the root causes [21]. They found that training data composition and model architecture alone don't explain the overrepresentation. The stronger signal came from RLHF: the aligned version of Llama was measurably less surprised by buzzword-heavy text than the base model, suggesting that human preference data amplifies these particular word choices during the alignment process.
The em dash question has its own explanation. Sean Goedecke's detailed Oct 2025 analysis points to training data composition as the strongest factor [22]. Between GPT-3.5 and GPT-4o, AI labs began incorporating more digitized print books as higher-quality training material. Em dash usage in English peaked around 1860, and classic literature leans heavily on the punctuation mark (Moby-Dick alone contains 1,728 of them). GPT-4o uses roughly 10 times more em dashes than GPT-3.5. The working hypothesis: state-of-the-art models draw heavily on 19th and early 20th century print books, which use significantly more em dashes than contemporary prose.
Then there are hallucinations, cases where models generate fabricated facts, nonexistent citations, or plausible-sounding nonsense with the same fluency and confidence as accurate statements. The mechanical reason is fundamental: the model's training objective is to produce the most probable next token, and it has no built-in mechanism for signaling "I don't know." Xu et al. proved in a 2024 paper that hallucination may be mathematically inescapable, arguing that LLMs cannot learn all computable functions and will inevitably confabulate when pushed beyond their training distribution [23]. Mitigation techniques like Retrieval Augmented Generation (RAG) and chain-of-thought prompting reduce the problem, but they don't eliminate it.
Understanding or mimicry
All of this leads to the field's deepest open question: do LLMs actually understand language, or are they what Bender, Gebru, McMillan-Major, and Mitchell called "stochastic parrots" in their influential 2021 FAccT paper [24], systems that stitch together linguistic patterns without any reference to meaning?
The evidence resists a tidy answer. Geoffrey Hinton, a Turing Award winner in deep learning, states directly that the idea these models simply pastiche stored text together "is nonsense" [25]. He argues that accurate next-word prediction necessarily requires the model to build deep internal representations of meaning. Ilya Sutskever, co-founder of OpenAI, frames it through compression theory: to compress text effectively, a neural network must learn something about the process that produced that text, not merely its surface statistics [26]. On the other side, Gary Marcus calls LLM outputs "unreliable mimicry" and argues that their understanding is superficial at best [27]. Yann LeCun occupies a nuanced middle ground, acknowledging that LLMs develop some conceptual understanding through attention-based clustering but insisting they lack physical grounding and the ability to truly reason or plan [28].
Empirical work has sharpened the debate. Othello-GPT, published at ICLR 2023 by Li et al., trained a GPT model purely on sequences of Othello game moves with no knowledge of the board, rules, or strategy [29]. The model achieved 99.99% accuracy predicting legal moves. When researchers probed its internals, they found an emergent representation of the actual board state. Modifying those internal activations to reflect a different board position changed the model's predictions accordingly, evidence that the representation was not just statistical noise but a causally active model of the game's structure. A 2025 replication study across seven different language models reinforced this finding [30].
Where does that leave you? Understanding this pipeline changes the relationship. You aren't conversing with a mind. You're working with a system that tokenizes your input, runs it through billions of learned attention operations, and rolls weighted dice over a probability distribution at every step, shaped at each stage by training data, architecture, and the preferences of human evaluators. That framing doesn't diminish the technology's practical value. It grounds your expectations in what these systems actually do, which is the foundation for using them well.
References
Sennrich, R., Haddow, B., and Birch, A. "Neural Machine Translation of Rare Words with Subword Units." Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016.
Kudo, T. and Richardson, J. "SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing." Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018.
Vivek, S., et al. "Problematic Tokens: Tokenizer Bias in Large Language Models." arXiv preprint, 2024.
Dubey, A., et al. "The Llama 3 Herd of Models." Meta AI Research, 2024.
Meta AI. "The Llama 4 Herd: The Beginning of a New Era of Natively Multimodal AI Innovation." Meta AI Blog, 2025.
Sevilla, J., et al. "Behind the Millions: Estimating the Scale of Large Language Models." Towards Data Science / Epoch AI, 2024.
"How Much Does LLM Training Cost?" Galileo AI, 2024.
Vaswani, A., et al. "Attention Is All You Need." Advances in Neural Information Processing Systems (NeurIPS), 2017.
Pichka, E. "What is Query, Key, and Value (QKV) in the Transformer Architecture and Why Are They Used?" 2023.
"GPT-4 Architecture, Datasets, Costs, and More." LifeArchitect.ai, 2023.
"Mastering LLM Techniques: Inference Optimization." NVIDIA Technical Blog, 2023.
Wang, K. "A Comprehensive Guide to LLM Temperature." Towards Data Science, 2024.
Holtzman, A., et al. "The Curious Case of Neural Text Degeneration." Proceedings of the International Conference on Learning Representations (ICLR), 2020.
Ouyang, L., et al. "Training Language Models to Follow Instructions with Human Feedback." Advances in Neural Information Processing Systems (NeurIPS), 2022.
Lambert, N., et al. "Illustrating Reinforcement Learning from Human Feedback (RLHF)." Hugging Face Blog, 2022.
Bai, Y., et al. "Constitutional AI: Harmlessness from AI Feedback." Anthropic Research, 2022.
Rafailov, R., et al. "Direct Preference Optimization: Your Language Model is Secretly a Reward Model." Advances in Neural Information Processing Systems (NeurIPS), 2023.
Sharma, M., et al. "Towards Understanding Sycophancy in Language Models." Proceedings of the International Conference on Learning Representations (ICLR), 2024.
Zhao, Y., et al. "From Lists to Emojis: How Format Bias Affects Model Alignment." arXiv preprint, 2024.
Kobak, D., et al. "Delving into LLM-Assisted Writing in Biomedical Publications through Excess Vocabulary." Science Advances, 2025.
Juzek, T. and Ward, M. "Why Does ChatGPT 'Delve' So Much? Exploring the Sources of Lexical Overrepresentation in Large Language Models." Proceedings of the International Conference on Computational Linguistics (COLING), 2025.
Goedecke, S. "Why Do AI Models Use So Many Em-Dashes?" Oct 2025.
Xu, Z., et al. "Hallucination is Inevitable: An Innate Limitation of Large Language Models." arXiv preprint, 2024.
Bender, E. M., et al. "On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?" Proceedings of the ACM Conference on Fairness, Accountability, and Transparency (FAccT), 2021.
Hinton, G. "How Language Models Mirror Human Thought." AI4 Conference, 2024.
Sutskever, I. "The Secret Sauce Behind Unsupervised Learning." Interview, The Decoder, 2023.
Marcus, G. "What Was 60 Minutes Thinking, in That Interview with Geoff Hinton?" The Road to AI We Can Trust (Substack), 2023.
LeCun, Y. "Interview on LLM limitations". Newsweek, 2024.
Li, K., et al. "Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task." Proceedings of the International Conference on Learning Representations (ICLR), 2023.
"Revisiting the Othello World Model Hypothesis." OpenReview, 2025.